

In modern IT environments, alerts are everywhere.
CPU spikes. Server latency. Application slowdowns.
Every small deviation triggers a notification — and yet, downtime still happens.
That’s the reality many IT teams live with today.
The issue isn’t that organizations lack alerts.
It’s that alerts alone don’t provide clarity.
Alerts tell you something went wrong. Insights explain why it happened, what’s likely to happen next, and how to prevent user impact. This shift — from alert-driven monitoring to insight-driven operations — is where ManageEngine clearly stands apart.

Why Alerts Alone Aren’t Enough
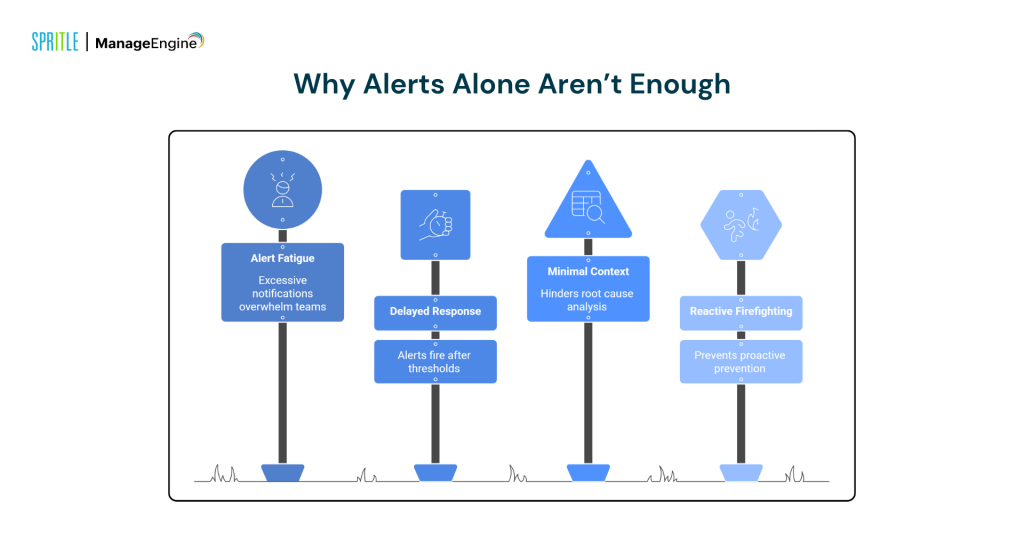
Traditional monitoring tools rely heavily on static thresholds and event-based triggers. While these alerts are useful, they come with real operational challenges:
- Alert fatigue caused by excessive, repetitive notifications
- Delayed response, since alerts fire only after thresholds are breached
- Minimal context, making root cause analysis slow and manual
- Reactive firefighting instead of proactive prevention
An alert that says “CPU usage crossed 90%” doesn’t explain what caused it, which application is impacted, or whether it’s a short spike or a warning sign of an outage.
As a result, IT teams spend more time reacting than resolving — increasing Mean Time To Repair (MTTR) and putting business continuity at risk.
Insights: The Real Driver of Downtime Prevention
Insights go far beyond surface-level metrics. They are built by analyzing trends, correlations, dependencies, and real user behavior across the IT stack.
Instead of asking, “What broke?”, insight-driven monitoring helps teams ask better questions:
- Why is this behavior abnormal?
- What changed before the issue appeared?
- Will this escalate if nothing is done?
- How will users be affected?
With the right insights, IT teams can:
- Detect performance degradation before outages occur
- Identify root causes faster through contextual correlation
- Forecast capacity and performance risks
- Align IT performance with real user experience
This is the foundation of ManageEngine’s monitoring philosophy — transforming raw metrics into actionable intelligence.
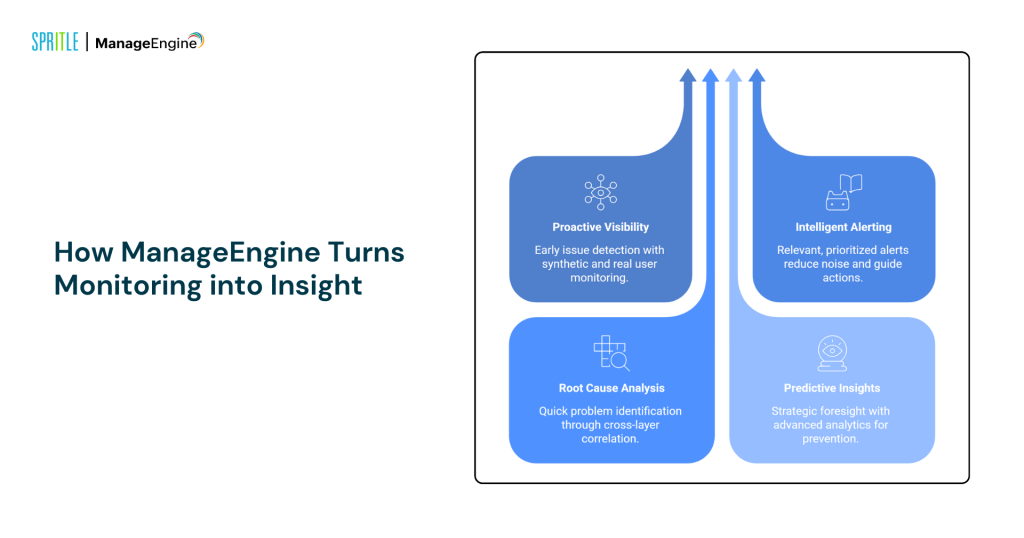
How ManageEngine Turns Monitoring into Insight
ManageEngine doesn’t treat monitoring as isolated data points. Its platforms unify performance data, user experience, and analytics into a single operational view that supports faster decisions.
1. Proactive Visibility with Synthetic and Real User Monitoring
With ManageEngine Applications Manager, teams gain both proactive and real-world visibility:
- Synthetic monitoring simulates critical user journeys to identify issues before users encounter them
- Real User Monitoring (RUM) captures actual user experience across browsers, devices, and geographies
This combination allows teams to spot slowdowns early and clearly understand how performance issues affect real users — not just infrastructure metrics.
2. Intelligent Alerting That Reduces Noise
Instead of overwhelming teams with alerts, ManageEngine focuses on relevance and context.
Key benefits include:
- Dynamic thresholds based on historical behavior
- Reduced false positives
- Prioritized alerts based on impact
- Context-rich alerts that guide next steps
Alerts stop being distractions and start functioning as meaningful signals supported by insights.
3. Faster Root Cause Analysis Through Correlation
Downtime is rarely caused by a single failure. More often, it’s the result of multiple dependencies breaking together.
ManageEngine enables:
- Cross-layer correlation between applications, servers, databases, and networks
- Distributed tracing to pinpoint performance bottlenecks
- Dependency mapping to visualize how issues propagate
This helps IT teams quickly determine whether the problem originates from infrastructure constraints, backend services, or third-party dependencies — without guesswork.
4. Predictive Insights with Advanced Analytics
With tools like ManageEngine Analytics Plus, organizations move from operational monitoring to strategic foresight.
Insight capabilities include:
- Performance and capacity trend analysis
- Incident and ticket pattern identification
- Resource utilization and cost optimization insights
These insights help teams prevent recurring issues, plan infrastructure upgrades, and make data-backed decisions — long before downtime becomes a business risk.
Insights in Action: A Real-World Scenario
Consider an enterprise application that frequently slowed down during peak business hours. Alerts were raised only after performance dropped — impacting users and revenue.
After implementing ManageEngine’s insight-driven monitoring:
- Trend analysis revealed recurring memory exhaustion patterns
- Correlated data identified specific APIs causing backend stress
- Predictive insights warned of future capacity saturation
The team optimized those services proactively — resulting in zero critical outages during high-traffic periods.
Why Insight-Driven IT Teams Win
Organizations that move beyond alert-only monitoring consistently experience:
- Reduced downtime
- Faster root cause resolution
- Lower operational stress for IT teams
- Improved end-user experience
- Stronger alignment between IT operations and business outcomes
Alerts notify.
Insights empower.
Final Thoughts: Move Beyond Alerts
Alerts will always play a role in IT operations — but they’re no longer enough.
In today’s complex, distributed environments, downtime prevention depends on understanding patterns, predicting failures, and acting early. ManageEngine enables IT teams to make that transition — from reacting to problems to preventing them altogether.
Because alerts tell you what broke.
Insights make sure it never does.