
In this blog I am going to share my experience in AngularJS file upload. I wrote rails application that will import CSV file data using Ruby’s built-in CSV library.
![]()
Frontend technologies : Boostrap with AngularJS. – It allow users to import records into the database by uploading a CSV file.
Background Job : Delayed Job – It helps to run longer task in the background.
Steps to import the CSV records:
1. Load AngularJS file upload plugin.
In application.js
[source]
//= require bootstrap
//= require angular-file-upload-shim.min
//= require angular
//= require angular-file-upload.min
//= require angular-resource
[/source]
2. Add the below code in your angular view page for users to upload CSV file.
[source]
%button.btn.btn-addon.btn-success{ “ng-file-select” => “”,
“ng-model”=>”product_file” ,
“ng-accept” =>”‘application/vnd.ms-excel,.csv'” }
%i.fa.fa-arrow-circle-o-up
Upload CSV
[/source]
3. Add the code snippet in your angular controller
[source]
app.controller “UploadCtr”, [“$scope”, “$upload”, “toaster”,
($scope, $upload, toaster ) ->
$scope.$watch(‘product_file’, ->
$scope.UploadProductData($scope.product_file)
)
$scope.UploadProductData = (files) ->
$scope.percent = 0
$scope.url = ‘api/v1.0/import_product/’
if file and files.length
i = 0
while i < file.length
file = file[i]
$scope.upload = $upload.upload(
url: $scope.url
file: file
).progress((evt) ->
$scope.percent = parseInt(100.0 * evt.loaded / evt.total)
console.log “percent: ” + $scope.percent
return
).success((data, status, headers, config) ->
# file is uploaded successfully
$scope.products = data.response
toaster.pop(‘success’, “”, “products is uploading as a background job.”)
return
).error((data, status, headers, config) ->
toaster.pop(‘error’, “File Upload Failed!”, data.response.message )
console.log data
return
)
i++
return
return
return
]
[/source]
4. Add this code in your rails controller
[source]
def import_product
data = params[:file].read
Product.import(data)
end
[/source]
5. Now we have to run the task asynchronously. I prefer to use delayed_job as it allows you to queue jobs in the database, and then process it asynchronously in the background. The gems like resque and Sidekiq also does the same job.
Add delayed job in Gemfile
[source]
gem “devise-async”
gem ‘delayed_job_active_record’
gem “daemons”
gem “delayed_job_web”
[/source]
Please read the delayed jobs best practices article which covers some of the practices to apply with Delayed Job.
Here, I migrated delayed jobs table with MySQL longtext Optimizations
Some exceptions received by Delayed Job can be quite lengthy. If you are using MySQL, the handler and last_error fields may not be long enough. Change their datatype to longtext to avoid this issue. If you are using PostgreSQL, this will not be a problem.
6. Go to Product model and write the following code block
[source]
require ‘csv’
class Product < ActiveRecord::Base
class << self
def importcsv(data)
begin
products = []
CSV.foreach(data, headers: true) do |row|
# csv file must be match with the column names of the product table
product = Product.new(row.to_hash)
products << product
end
Product.import products, :validate => false
# send you email notification
Notifier.delay.send_claim_file_upload_status(“Successfully Uploaded”,
‘prabud@wp.spritle.com’)
rescue Exception => e
Notifier.delay.send_claim_file_upload_status(e.message,
‘admin@wp.spritle.com’, ‘Product load – Failed’)
end
end
# run the import job as a backgound job
handle_asynchronously :importcsv, priority: 2,
run_at: Proc.new { 3.seconds.from_now }, queue: ‘products’
end
def self.import(data)
Product.importcsv(data)
end
end
[/source]
Run the application. Everything works fine until I decided to upload the maximum size of files.
I wanted to upload 2MB file and then I got an error “Connection was reset while the page was loading”.
See my console and nginx error logs.
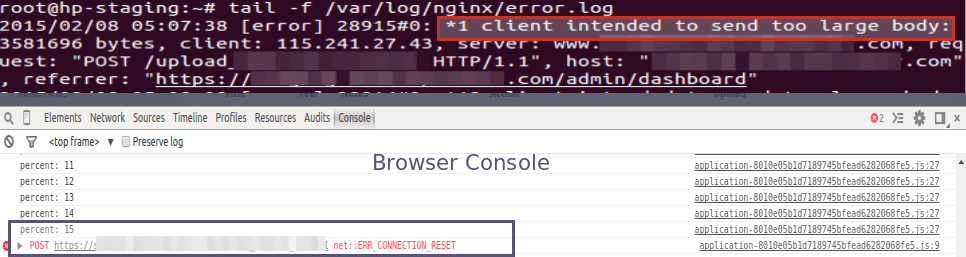
To fix this issue, we need to set the below configuration in nginx.conf file.
[source]
client_max_body_size 5M;
[/source]
Restart the nginx and run the delayed job services.
That’s it.
Thanks
happy coding 🙂
Pretty good post but I have some questions for you:-
1. What was the intuitive thought behind using delayed_job?
2. Why not use some disk base cache(eg Redis) to store the jobs and save extra trips to database?
My Thought:-
In my understanding delayed_job uses SQL database for storage and processes jobs in a single-threaded process. It can be setup fast but lacks the performance and misses the scalability. It is generally used where load on DB is not a thing to worry and total job load is pretty less.
Other choices are resque and sidekick, which uses redis for job storage and processes messages via workers. Major advantage of using sidekick is that it is multithreaded where as resque is single threaded. Sidekick has that raw speed which we look in the multithreaded application. Only catch is that processor code should be thread-safe.
Thank you so much for you reply Khushwant Jhaj 🙂
I usually prefer delayed job for the situations where there are not many jobs. In those cases it does not make sense to have a Redis dependency. But for most of our Production applications we use Sidekiq mainly because of the reasons you pointed out.