
Internal Working of Apache Storm
What is Apache Storm ?
Apache Storm is one of the best distributed framework for real time processing of Big Data. It is free and open source, licensed under Apache License, Version 2.0. It makes us easy to process unbounded streams of data. Most important thing is that, it can be used with any programming languages.
Integration with Queueing and Database Systems
Storm integrates with any queueing and database systems which we already use. Kestrel, Kafka, JMS, Amazon Kinesis and RabbitMQ / AMQP are considered as some of the queueing brokers. Similarly, integrating storm with the database systems is very simple. MongoDB, Cassandra, RDBMS’s are examples of database systems. Simply open a connection to our database and read / write as what we normally used to do. Storm will handle the parallelization, partitioning and retrying on failures when necessary.
Components of Apache Storm
The storm comprises of 3 abstractions namely Spout, Bolt and Topologies. Spout helps us to retrieve the data from the queueing systems. Spout implementations exist for most of the queueing systems. Bolt used to process the input streams of data retrieved by spout from queueing systems. Most of the logical operations are performed in bolt such as filters, functions, talking to databases, streaming joins, streaming aggregations and so on. Topology is a combination of both Spout and Bolt. Data transferred between spout and Bolt is called as Tuple. Tuple is a collection of values like messages and so on.
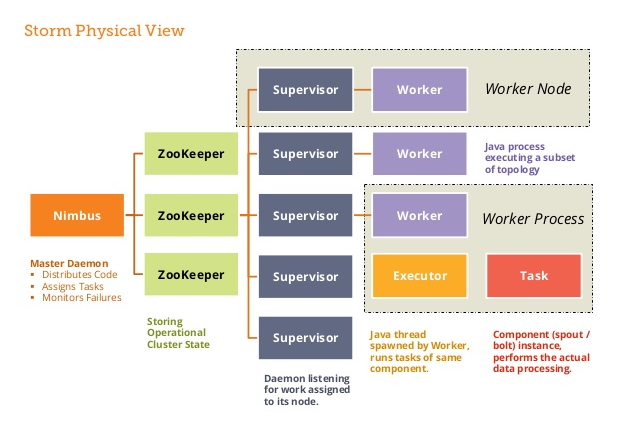
Nodes of Apache Storm
A Storm cluster has 3 sets of nodes namely Nimbus, Zookeeper and Supervisor nodes. Nimbus node is also called as a master node and acts as a job tracker. It is responsible for distributing the code among supervisors, assigning input data sets to machines for processing and monitoring for failures. Nimbus node relies on zookeeper service to monitor the message processing tasks as all the supervisor nodes update their tasks status in zookeeper node. Zookeeper node acts as an intermediate between nimbus and supervisor node. Communication and data exchange takes place with the help of zookeeper node. It helps to coordinate the entire cluster. Supervisor node is also called as worker node and acts as task tracker. It receives the assigned work to a machine by nimbus service. It manages work processes to complete tasks assigned by Nimbus. It will start and stop the workers according to the signals from Nimbus. All supervisor nodes are interconnected with each other with the help of Zero MQ (Messaging Queue). The tasks from one supervisor node can be transferred to another by using Zero MQ.
Fault-tolerant
When workers die, Storm will automatically restart them. If a node dies, workers will be restarted on another node. Nimbus and Supervisors are designed like stateless and fail-fast. So if they die, it will restart like nothing happened. So we can kill it by using “-9” without affecting cluster or topologies.
Guarantees Data Processing
Each and every tuple will be fully processed in storm. Spouts and bolts can be defined in any language. Storm clusters are easy to deploy, requiring a minimum of setup and configuration to get up and running. It is easy to operate once deployed and designed to be extremely robust.
For Further Reference
storm.apache.org
Currently my research on external working of Apache Storm is in progress. Let you know about it in my upcoming blogs.
Lots and lots of thanks to all for spending your golden & precious time. Have a great day.