
Introduction
Hello, everyone! Trust you’re in good spirits.
In 2023, an AI application took the global stage by storm and captured the world’s attention – none other than ChatGPT. As ChatGPT is swiftly solidifying its place as a household term, in this blog, we’ll delve into the magic that drives it – Generative AI algorithms.
Join us in exploring Generative AI from an industry standpoint and exploring its potential in shaping the products of the future.
Advent, and the Need for Generative AI
Like any other invention, Generative AI (Gen AI) is also built progressively by the effort of several researchers who all contributed at different stages and some major milestones shaped the current world of Gen AI.
It’s important to understand the history of something to have a strong foundation and understand why something is built the way it is.
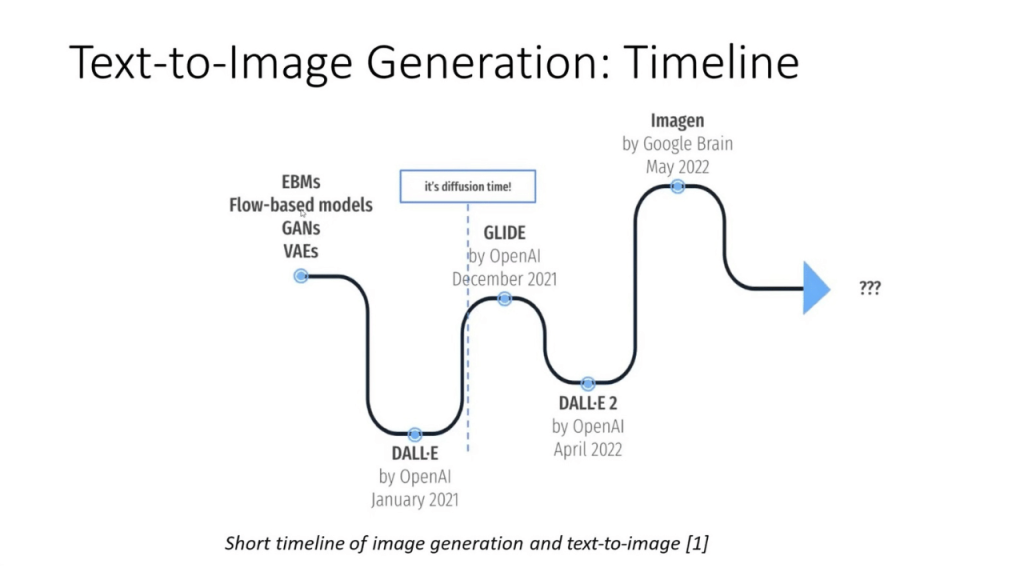
This image provides a quick overview of how quickly the field of AI is expanding with new major releases and improvements releasing in quick succession.
Here, let’s try to look at the intuition behind each algorithm, rather than the real magic behind the scenes – math.
History of Generative AI
Well, before we quickly jump into the world of vision we have to talk about the OG revolutionary algorithms- CNNs or Convolutional Neural Networks.
- Early CNNs
Intuition: Some features of the image are more important than others. Using these features we can build a complex nonlinear function (or a DL model) that can give a rigid/desired/explicitly mentioned output.
Backpropagation is the key to the success of CNNs, we can have an input, we can generate the output, and then find the distance or loss and use that to update the weights or parameters of our nonlinear function.
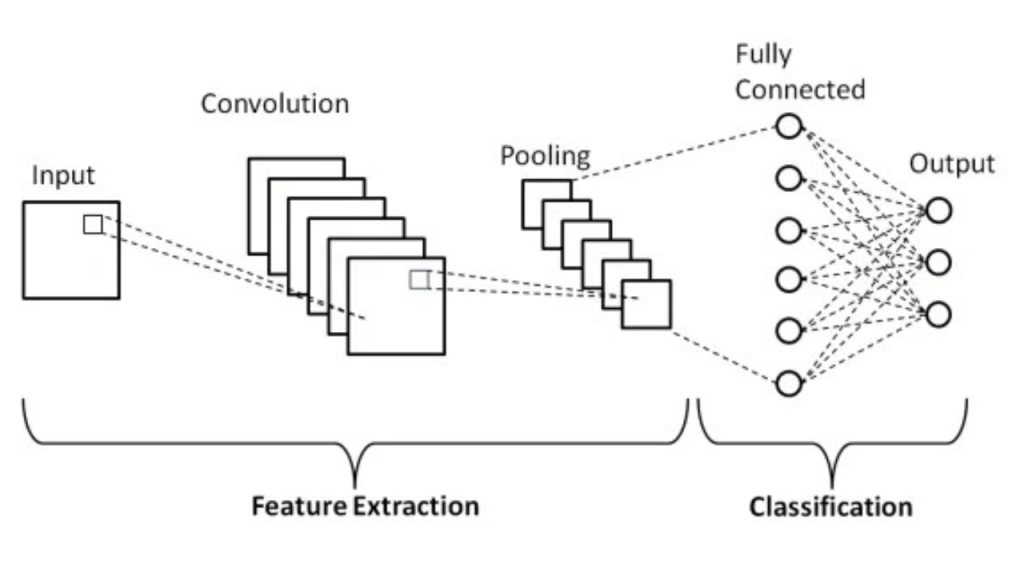
Groundbreaking research using techniques like AlexNet, RCNN, SSD, Yolo and many others has proved extremely crucial to solving some of the most complex problems in CV.
While they have ruled the world of computer vision since the 2010s, they could only be used for discriminative tasks like classification or object detection.
2.Transformers
While all of this was happening in Computer Vision, the Natural Language Processing field also had its own set of revolutionary ideas in the form of transformers.
Transformers have a unique implementation called self-attention. This was introduced in one of the most famous papers: Attention Is All You Need
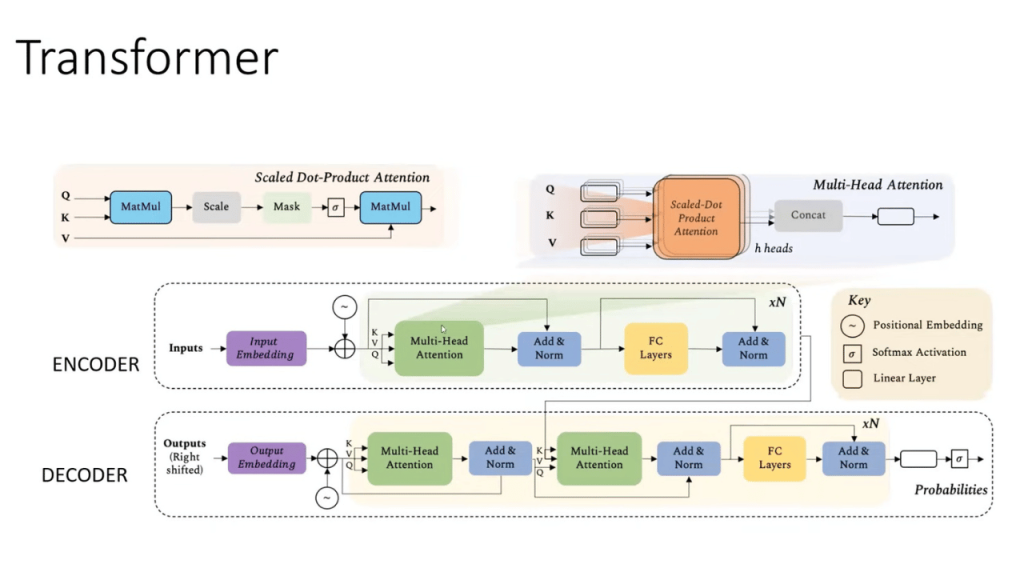
They are being extensively used in the field of machine language translation and comprehension. It is best suited for NLP tasks due to their ability to capture contextual information, handle long-range dependencies, and scale effectively with large datasets.
However, it couldn’t be used for images since the processing power needed to run it is huge and impractical.
The computational complexity was solved in a paper – “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”[4] where the image is broken down into several patches and the relation between those patches is established using self-attention.
Another important paper that figured out how object detection can be done using ViT and won the Marr Award for their efforts is “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows”[5]
It’s also important to look into Cross-Entropy and KL Divergence algorithms at this point. This is an interesting concept that we will discuss in later blogs.
3.GANs
Although Auto Encoders are probably introduced before GANs, let’s first learn about GANs
GAN is a short form for Generative Adversarial Networks
Intuition: Why should we have a fixed input that is usually a long vector with some significance like an object’s position or the probability of a class? Why not have the output itself as another image?
This was the question that was explored by Ian Goodfellow [9] in his brilliant paper Generative Adversarial Networks
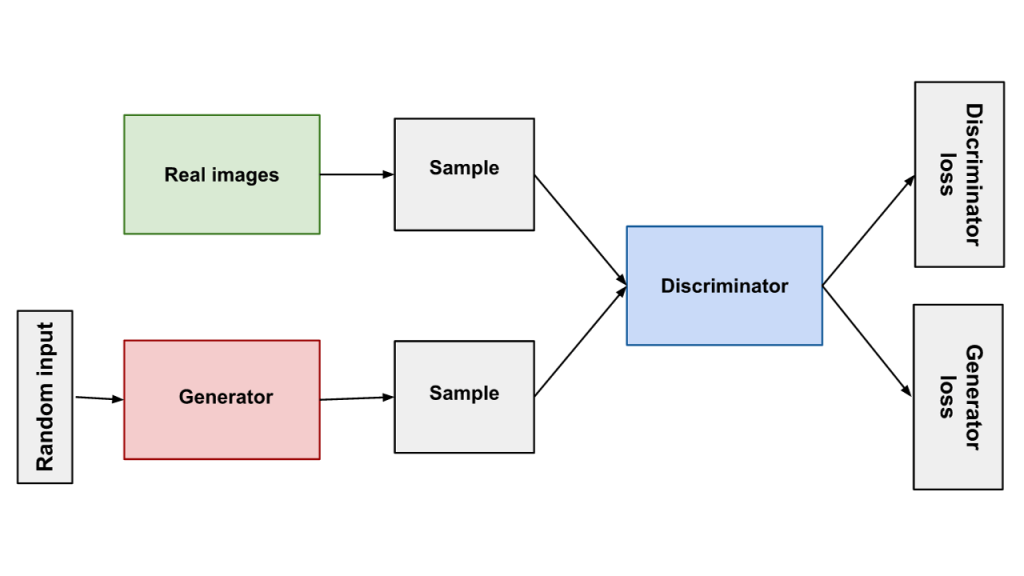
This approach consists of a generator which, as its name suggests, is responsible for generating images.
Some of you may start wondering – But how do we determine if the image is the required output and not just some random image the machine deemed fit to throw out?
Well, we have another network called a discriminator which tells the generator how wrong its image is.. might seem harsh.. but it worked!
Later versions like DCGANs (2016) which uses deep convolutional layers, produced low-quality images. To fix this, LAPGAN was proposed which had a higher resolution but it suffered from fuzziness.
The limitations of GAN are its sensitivity to hyperparameters and high inference times.
4.VAEs
VAEs are Variational AutoEncoders. First, let’s talk about Auto Encoders.
Intuition: Auto Encoders also generate images, but they generate images by reducing the dimension of the image and then increasing it to an image dimension.
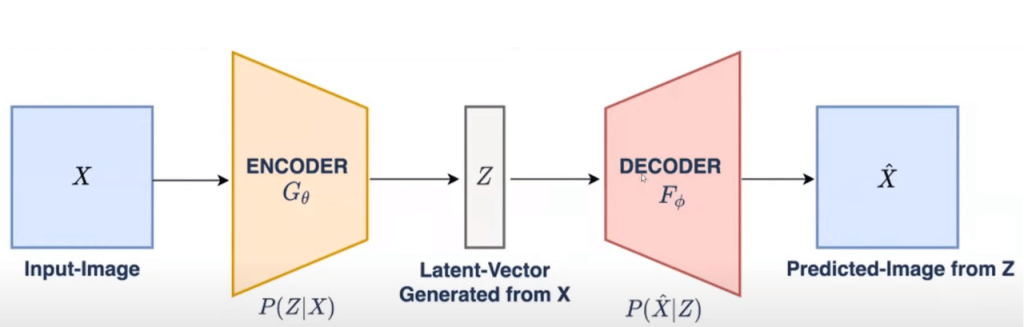
However, there are some problems with this approach, mainly because the data is clustered into categories which will not help in generating an image that might overlap categories
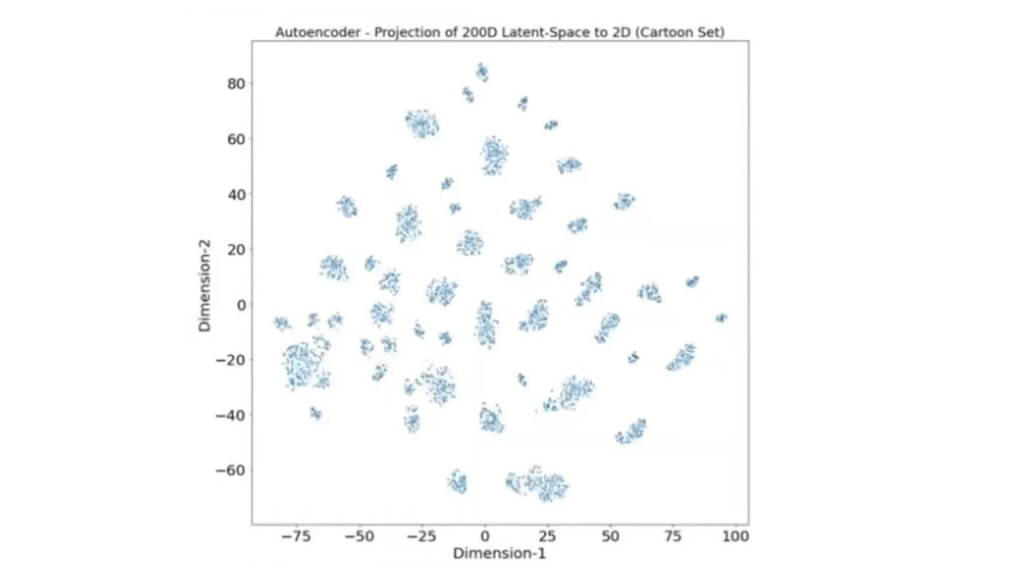
How can we solve this problem and make it a continuous space? Simple, smoothen it!
Let’s add a smoothing function before the latent vector and it should take care of it.
To smoothen it we use a bell distribution.
Now the latent vector is estimated using the mean, variance, and standard deviation of the distribution function.
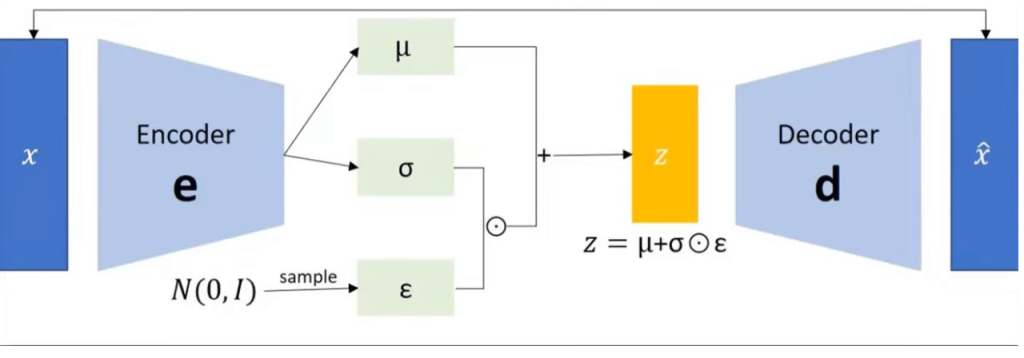
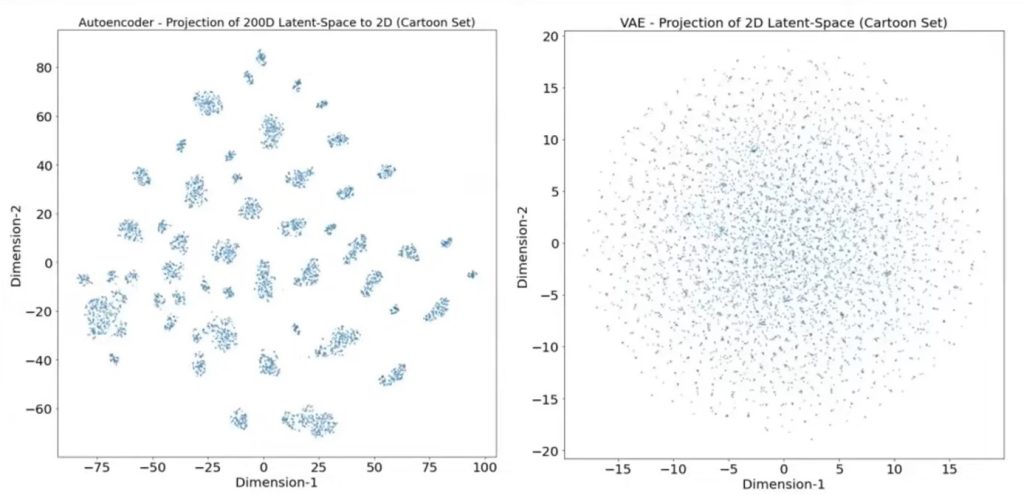
Even with this, the image transition is not very smooth so another addition is made to this which is called a VQ-VAE – Vector Quantized VAE
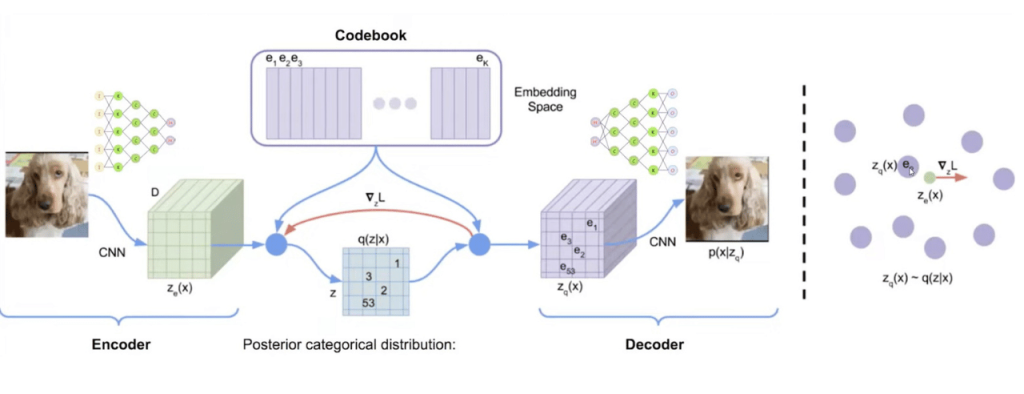
5.Diffusion Models
Intuition: In VAE, what if we make the input image and the target image the same? [Disclaimer: it’s not that simple]
The resulting model is called a Diffusion model, where an image is taken to a noise image and is brought back to the original image.
The better and best explanation of one of the most important models is covered in [2]
In conclusion, the significant model types in GenAI look like this[2]:
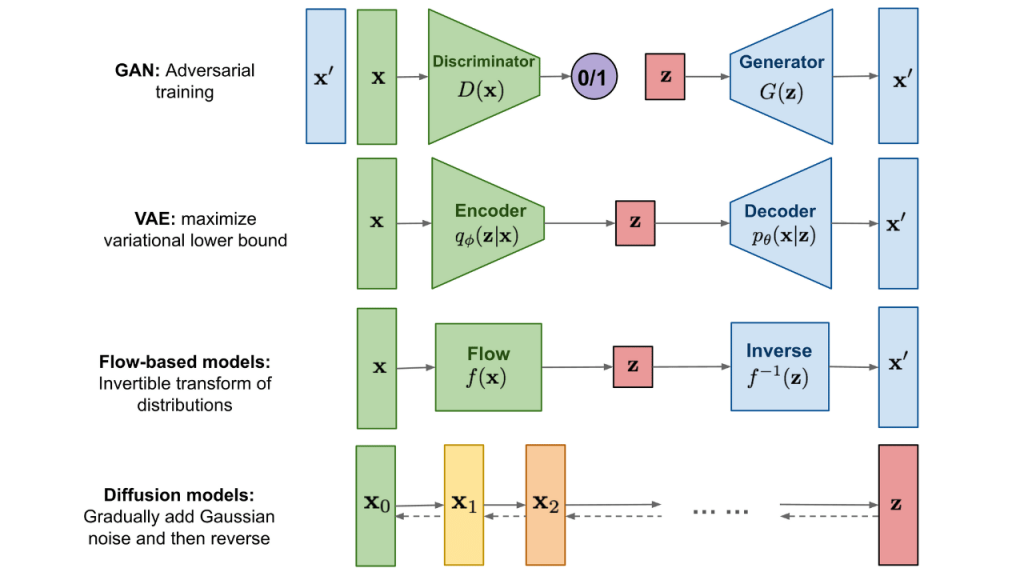
Popular Models:
Since we covered the basics of GANs, VAEs, and Diffusion Models. Let’s look at some examples of popular models that use these concepts.
1.CLIP
Clip is a model released by OpenAI. The best thing is it’s open source. It’s Multimodal. Has Zero-Shot Learning. And it uses Contrastive Language.
Too many new terms? No worries! Let’s try to look at them one by one.
Multimodal simply means it can work with different types of data, text, and images.
Contrastive Language is a technique that is used by CLIP to understand that similar representations should be close to the latent space.
WAIT A MINUTE! Didn’t we see this latent space somewhere?
That’s right! It’s the concept that we just discussed in VAEs. And what’s the whole thing about it being multimodal? How does it help?
Well, think about it this way. If we can represent a text as a vector and if we can represent an image as a vector, then what if both the vectors are the same? [nearby or similar or the dot product is zero]. Then can’t we jump from text space to image space? That’s right! We can! And we did!
As we have seen in both Diffusion Models and VAEs, images can be generated from latent space. So if we can generate the latent vector from texts and images and make them the same then we can go from one dimension to another! In both directions.
CLIP used 400 Million (40 Crores) image-text pairs to achieve this incredible feat.
It has 2 concepts [8]:
- Contrastive pre-training
- Zero-Shot Learning
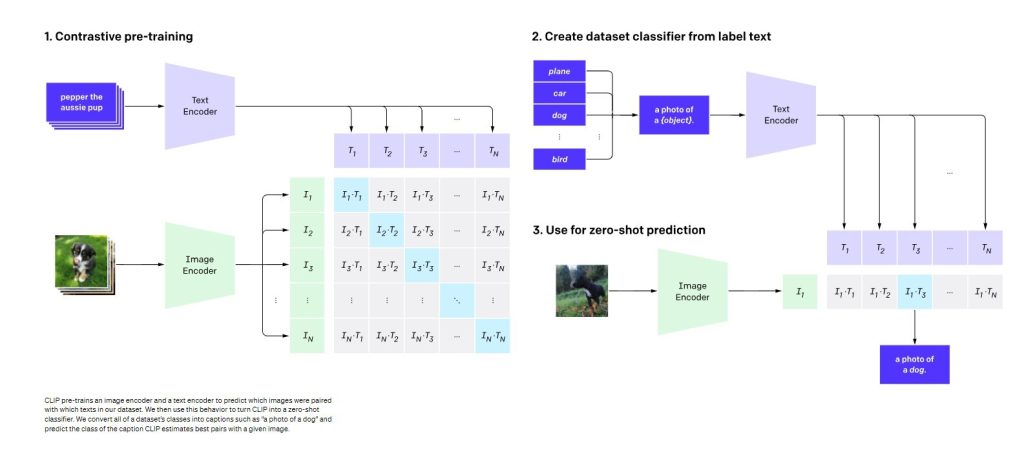
2. DALL.E
DALL.E, also from OpenAI, uses CLIP. Based on the VQ-VAE type of model. It is a text-to-image
model that generates images from text prompts.
DALL.E 2 uses a diffusion model conditioned on CLIP embeddings.
Journey of DALLE.2

Here is a simple image generated by DALL.E in about a minute
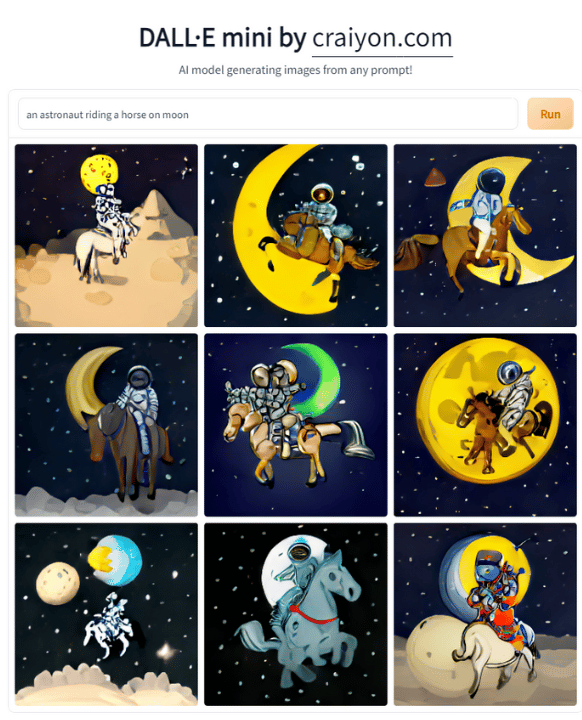
You can also try it now at: https://huggingface.co/spaces/dalle-mini/dalle-mini
Many other models like Stable Diffusion and MidJourney produce even better photorealistic images.

You can also try Stable Diffusion at: https://huggingface.co/spaces/stabilityai/stable-diffusion
Give them a try in your free time! Let’s discuss more about those in the next blogs!
Applications
Now that we have seen various models, how they were developed, and what they are capable of generating, it’s time for us to discuss where and how these models can help us now and in the future.
- Data Creation
- The, perhaps, most obvious use of Gen AI is in generating images. When developing and handling computer vision data, it often faces problems like data privacy, licenses, and other roadblocks.
- Generating data purely from text is a dream come true for many companies that want to leverage using (now) traditional models like object detection and classification.
- It often helps in cases where data just might not be available. Images of things like fire, smoke, and production defects may not be readily available, or simulating those scenarios carries an inherent risk and can incur huge costs. Gen AI comes in handy in these scenarios.
- Data Augmentation
- Sometimes we might have images, but those images might be so few that they are not sufficient for models that require a minimum of 5000 images to function properly without overfitting, like Yolo V8.
- Traditional augmentation techniques like contrast, rotation, and other techniques might produce unrealistic data as well.
Genarative AI using style transfer techniques will come in handy in these scenarios.
There are companies like Kopikat that are doing exactly that!
- 3D model creation
- The Generative AI (Gen AI) techniques can be extended to create even 3D models of objects which can be used to create games easily and faster!
Checkout MeshyAI a tool that does just that.
- Image Editing
- Genarative AI can be controlled to produce the desired output like style transfer, image compositing, sketch to image. [7]

Conclusion
The key takeaway from this blog is the fact that Gen AI is a collaborative effort of many researchers, each contributing in their own way to the success of these innovative algorithms.
The potential of Generative AI models is vast, ranging from enhancing human creativity to automating complex tasks.
However, it is imperative to approach their deployment with ethical considerations in mind.
As these models become increasingly sophisticated, issues related to bias, transparency, and accountability must be addressed to ensure responsible AI development.
Looking forward to sharing more things with you like the grounding models such as GLIGEN in the next blog!
Please feel free to share your thoughts and things I might have missed in the comment section!
References
- CAP6412 Advanced Computer Vision – Spring 2023 – UCF CRCV
- https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
- https://developers.google.com/machine-learning/gan/gan_structure
- https://arxiv.org/abs/2010.11929
- https://arxiv.org/abs/2103.14030
- https://medium.com/techiepedia/binary-image-classifier-cnn-using-tensorflow-a3f5d6746697
- https://github.com/ermongroup/SDEdit
- https://openai.com/research/clip
- https://www.technologyreview.com/2018/02/21/145289/the-ganfather-the-man-whos-given-machines-the-gift-of-imagination/